CIGEval——LMM条件图像生成评估框架
条件图像生成 | Conditional Image Generation
什么是条件图像生成
条件图像生成是指根据用户给定的控制信息(文本、图像、布局、视觉信号等)LMM生成符合特定条件的图像的任务。其核心目标是学习从条件输入到目标图像的映射关系,实现可控、高质量的图像生成。

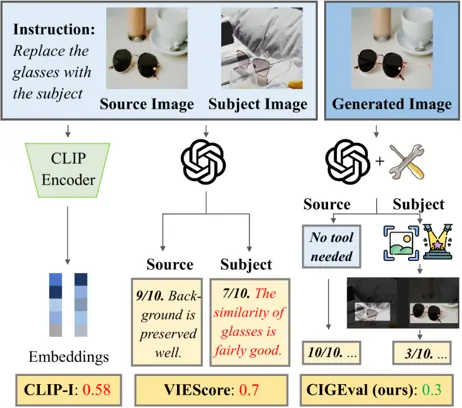
上图就是一个简单的例子:给大模型两个图像,要求用subject image这种的墨镜替换source image中的墨镜,右侧是大模型根据要求生成的图像。
核心关注点
-
语义一致性:条件是否达成
-
视觉质量与真实性:生成图像要保证符合物理规律,并且保证图像的光影,色彩等视觉上的质量
-
推理效率与实时性:CPU占用、生成速度(fps)等
-
伦理与安全:防止生成有害内容和侵犯他人隐私的内容等
应用场景与技术价值
| 领域 | 应用 | 技术需求 |
|---|---|---|
| 电商 | 商品图生成,虚拟模特试衣 | 图文生成 |
| 游戏/影视 | 角色/场景生成/风格化渲染 | 个性化定制+图像合成 |
| 工业设计 | 产品原型生成、室内布局可视化 | 布局控制+视觉信号转换 |
| 医疗/遥感 | 医学影像增强、卫星图修复 | 图文生成+图像编辑 |
| 自动驾驶 | 鸟瞰图生成(DiffAD模型) | 多任务统一表示 |
评估指标或模型
如果想要图像生成任务取得较为理想的效果,就需要对LLM生成的图像进行评估,现有的常见评估指标和模型大致分为三大类。
通用图像生成指标
-
FID:通过Inception-v3网络提取特征,计算生成图像与真实图像分布之间的Frechet距离,但无法直接评估语义对齐
-
IS:基于生成图像在分类模型(Inception Net)中的概率分布熵,同时衡量清晰度和多样性
-
KID:FID的无偏估计版本,基于最大均值差异(MMD),只适用于小规模数据集的评估任务
感知质量与真实性指标
-
LPIPS:通过预训练网络提取特征,计算两图像的感知差异,适用于评估风格迁移、图像修复等任务的视觉自然度评估
-
SSIM:从亮度、对比度、结构三个维度评估图像相似性,仅适合轻度编辑任务的评估
-
NRQM:无需参考图像,直接评估生成图像的清晰度、伪影等
语义一致性评估指标
-
CLIP Score:使用CLIP模型计算文本描述与生成图像的嵌入余弦相似度,评估图文对齐程度,适用于文本引导生成编辑任务
-
DINO-ViT特征相似度:利用自监督ViT模型提取深层特征,计算生成图像与参考图像的语义相似性,适用于对复杂编辑任务中的语义变化敏感的评估任务
当前的评估指标或模型有三个限制:(1)特定于任务(2)可解释性有限(3)缺乏人类对齐
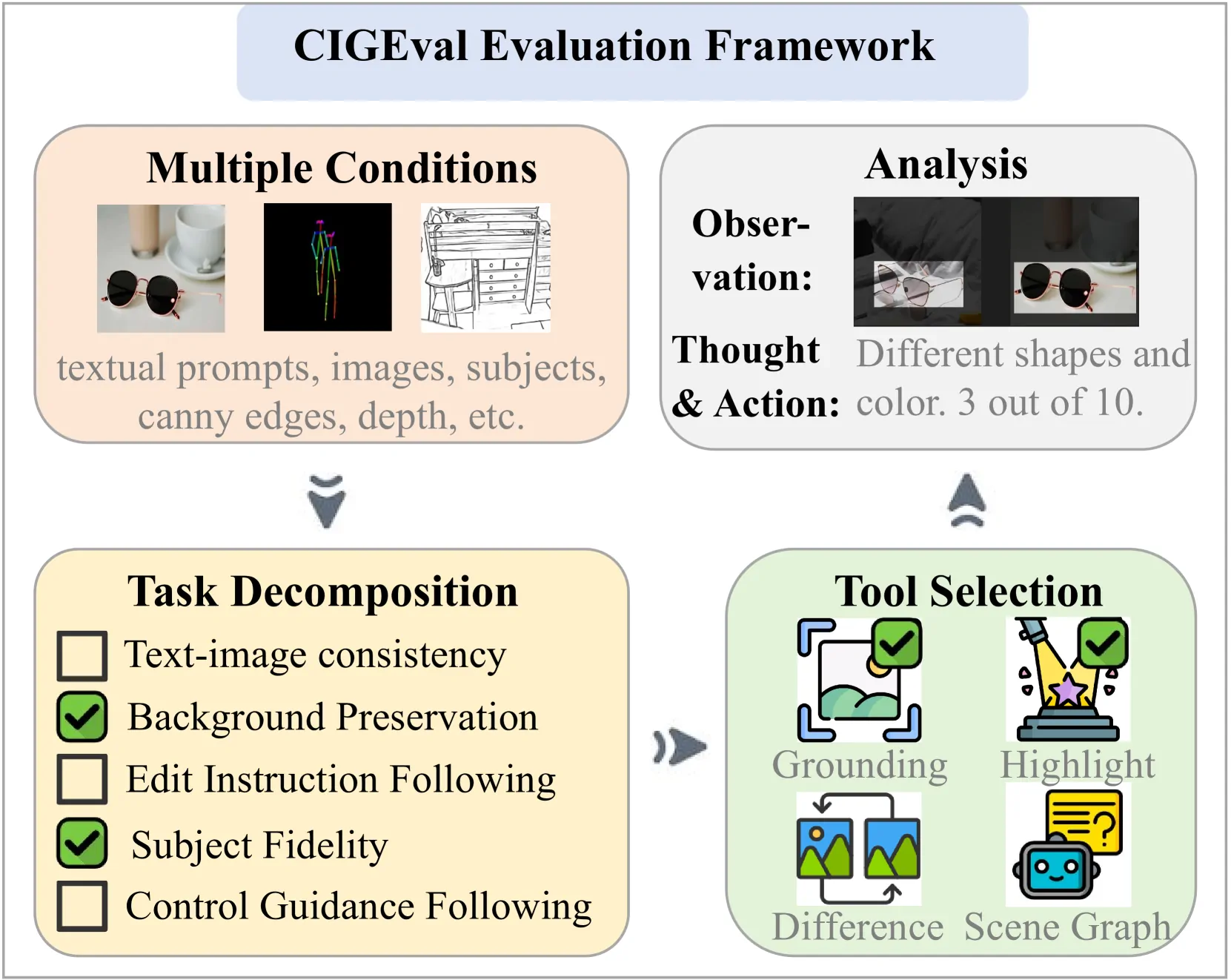
CIGEval:用于评估条件图像生成的统一代理框架
什么是CIGEval?
CIGEval是一个基于 LMM 的自主代理框架,用于评估条件图像生成。该代理框架可以集成先进的 GPT-4o 模型和开源模型
(1) 在没有人工协助的情况下做出独立决策和判断的自主评估
(2) 使相对较小的模型能够有效地执行复杂的评估
研究背景与意义
传统的图像评估方法往往侧重于图像与给定条件的对齐程度或图像的感知质量,但这些方法往往存在任务特异性、解释性差以及与人类评估相关性不高的问题。特别是在处理涉及多个条件或复杂控制信号的条件图像生成任务时,传统方法往往难以全面、准确地评估生成图像的质量。
CIGEval克服传统评估方法的局限性,通过整合LMM和多功能工具箱,实现对生成图像的细粒度评估。
CIGEval评估框架
任务定义
模型对评估任务定义为:
输入:
- I :评估指令(如:检查主题一致性)
- O:待评估的生成图像
- C*:条件集合
输出:
- Rationale:推理过程(自然语言)
- Score:评分(0.0-1.0)
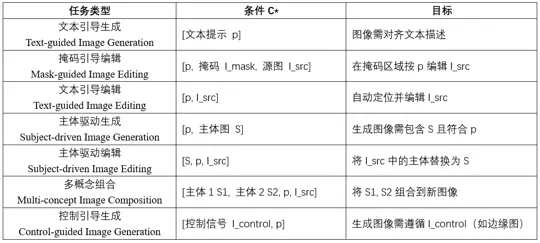
七类条件生成任务
条件图像生成任务中的条件公认被划分为七大类,作者将这七大类任务整合成表中这种比较规整的表示方式作为C*的输入格式。
工具箱
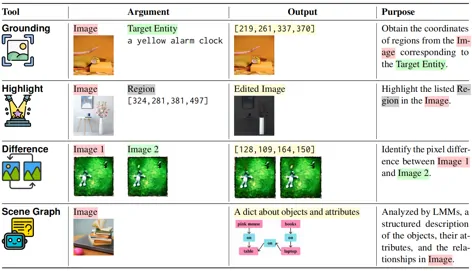
CIGEval提供一个工具箱包括:
- Grounding——用于定位某一物体
- Highlight——高亮显示某区域
- Difference——检测两幅图的像素级差异
- Scene Gragh——解析图像结构
模型推理过程
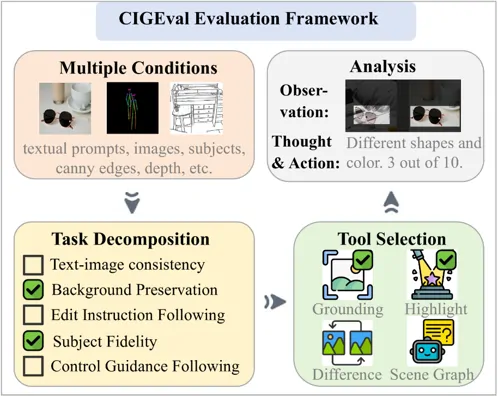
模型在推理过程中,首先处理输入的条件、原始图像等多模态信息;再由大模型自主将评估目标进行分解,比如:采用划分细粒度子问题并评估的策略、图像是否按照提示进行、图像编辑是否按照说明进行、图像是否在不更改背景的情况下执行最小编辑、图像中的对象是否跟随提供的主体、图像是否遵循控制引导等;然后在每一个评估目标的评估上,模型必须调用工具箱进行评估,评估过程中也有LLM自主学习使用哪些个工具,如何组合使用;最后将每一个分解后的评估目标得到的评分进行合并,如下式所示,合并过程取最低评分作为这个任务的最终评分,这样设计的意图是任意一个子任务失败,则整体评分都应该低。这一整个评估过程使用的都是GPT-4o模型。
训练集构造与模型微调
轨迹数据合成
将GPT-4o模型得到的结果整合成一个轨迹数据,一个轨迹数据包括四部分:观察、思考、动作、结果。以上文提到的替换墨镜任务为例,它的轨迹数据就应该如下图所示,Observation记录的其实就是作者在任务定义公式中的输入,然后一个Thought-Action-Tool Output记录的是大模型自主思考以后划分的一个子问题及对应的评估过程中使用什么工具解决的过程,最后得到一个整体评分,分数应该介于[0,10]。

数据集来源
将以上过程应用在ImagenHub数据集上,得到对应的轨迹数据集,同时人工对ImagenHub数据进行评分,剔除掉与人类评估结果差距过大的样本,剩下的高质量轨迹作为小参数量模型微调训练集。因为加入了人工评分的过程,人类评分习惯性使用[0,10]进行评分,所以才设计大模型的评分结果为[0,10]。
- 使用ImagenHub数据生成轨迹
- 人工对ImageHub数据进行评分
- 剔除最终评分与人类评分差异较大的轨迹,剩余样本作为训练集
Agent Tuning
模型:Qwen2-VL-7B / Qwen2.5-VL-7B
输入:轨迹序列 {o₀, t₁, a₁, o₁, …, tₙ, aₙ, oₙ}
训练目标:
Q:为什么设计轨迹数据?
A:这样的数据集能记录GPT-4o的思考方式与决策逻辑,让GPT-4o作为“教师模型”训练参数量较小的模型:学习何时调用工具、学习如何使用工具推理输出、学习生成可解释的评分理由,让小模型学习如何思考和决策。
实验结果
- 核心实验
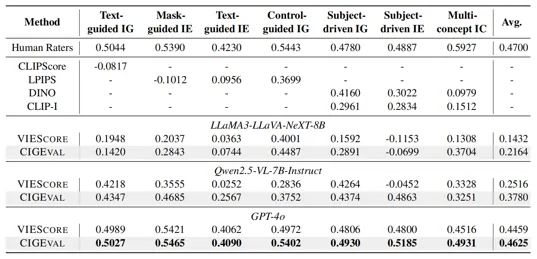
这个表展示了以不同 LMM 为backbone的 7 个条件图像生成任务的 Spearman 相关分数。缩写“IG”、“IE”和“IC”分别代表“图像生成”、“图像编辑”和“图像合成”。“-”表示不适用。
当使用 GPT-4o 作为底层 LMM 时,CIGEval 在所有 7 个任务中都实现了最先进的性能。它与人类评分者的平均 Spearman 相关性为 0.4625,与人的相关性非常匹配。在涉及多种条件的任务中都有明显提升,例如控制引导生成(Control-guided IG)和多概念组合(Multi-concept IC)任务,在以前的评估指标在这些任务中表现不佳。
- 消融实验
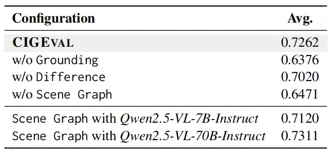
这个表展示了不同配置的 CIGEval (GPT-4o) 中工具的消融研究。
为了评估 CIGEval 中每种工具的必要性,作者做了一项消融研究。Highlight 无法单独使用,通常伴随着 Grounding 和 Difference,所以不对 Highlight 进行特定的消融。表中结果展示完整的 CIGEval 配置达到了最高的平均分 0.7262。当每个工具被移除时,会观察到明显的下降,每一个工具的设计都必不可少。
- 与SOTA的对比结果
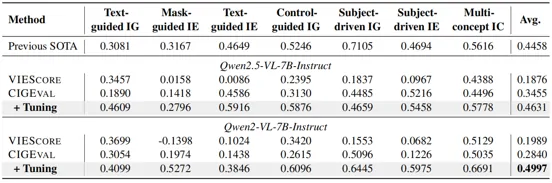
这个表展示了使用基于开源小型 LMM 的 VIEScore 和 CIGEval 跨 7 个任务的 Spearman 相关分数。这里的“Previous SOTA”是指基于 GPT-4o 的 VIEScore。
表中结果战术了Qwen2-VL-7B-Instruct 和 Qwen2.5-VL-7B-Instruct 在微调后分别由明显的相关性提升,微调后的 7B 模型超越了以前最先进的基于 GPT-4o 的 VIE Score模型。
总结与思考
- 评估框架需兼顾全面性与可解释性
CIGEval的智能体框架通过工具链实现动态问题拆解。评估结合量化指标与可解释路径,避免黑箱评分。
相关文献
MMIG-Bench:首个统一多模态图像生成评测基准,通过三层可解释指标评测,实现全面评估模型在文本&图像联合输入下的生成能力,解决传统评估中多模态条件割裂与细粒度对齐缺失的痛点。
- 人类偏好对齐
CIGEval在七个条件图像生成任务中与人类的评分非常接近挑战:
(1)主观偏差:人类评分需多标注者共识,受人主观因素影响严重。
(2)自动化替代:CIGEVAL通过微调7B小模型(Qwen-VL)仅用2.3K轨迹数据即超越GPT-4o基线,证明高质量合成数据可迁移人类偏好。
- 小模型潜力
CIGEVAL证明7B模型经微调可超越GPT-4o,关键在高质量轨迹数据(如工具调用逻辑、人类评分对齐)。
相关文献
A*-Decoding:该方法将语言模型解码过程建模为状态空间搜索,应用了 A* 搜索算法,利用一个外部过程监督信号作为启发函数来评估部分推理路径的质量和潜力,从而在固定的计算预算下,智能地优先探索最有希望的推理路径,使参数量较小的LLM能媲美甚至超越大得多的LMM的推理表现。
- 落地实际应用上
框架仅评估语义一致性,应拓展更多工具来评估更多指标,如:
(1)视觉质量:评估图像清晰度,色彩自然度,纹理细节,光影等
(2)条件符合度:细粒度图文对齐,基于问答的图文一致性评分等
(3)伦理与安全:过滤有害内容
多评估指标的结果根据需求对每一指标加不同权重权进行聚合。
以上就是本片文章的全部内容了,感谢观看!!!
 微信
微信 支付宝
支付宝